포트폴리오 구축 방법은 "파이썬 증권 데이터 분석" 책을 참조해서 쓰여졌습니다.
포트폴리오를 구축하기 위해서 수익률과 리스크를 기반으로 샤프(sharpe) 지수를 구하고
이를 몬테 카를로(Monte Carlo) 시뮬레이션으로 반복한 후 샤프지수가 가장 높은 값으로 종목을 선택하게 된다.
<< 순서 >>
1. 관심종목 4개를 선택(CJ, LG 디스플레이, 삼성전자, SKT)하여
2. 몬테 카를로 시뮬레이션을 10,000 번 수행한다.
3. 그리고 마지막에 샤프 지수로 정렬한다.
이제 차근차근 시작해보도록 하자!
우선 데이터 대시보드의 상단의 데이터 입력 부분이다.
대시보드 편집에서 "입력 추가"에 "다중 선택"을 추가한다.

연필 모양을 클릭한다!!
"Dynamic Options(동적 옵션)" 탭에 검색 문을 입력한다
| inputlookup kospi_200.csv | table code name

"Field For Label (레이블로 사용할 필드)" 은 화면에서 보여지는 리스트로 "name" 필드를 선택한다.
"Field For Value (값으로 사용할 필드)" 는 변수로 입력되는 부분으로 "code" 필드를 선택한다.
다음은 "Token Options(토큰 옵션)" 탭으로 이동한다.
여기에서는 다중 선택된 변수들을 조합해서 검색문을 만드는 부분이다.

"Token(토큰)" 은 "codes"로 설정하고 실제 이 값이 변수 이름으로 할당 된다.
다음은 변수 값을 만들어 주는 설정이다.
"Token Value Prefix(토큰 값 접두사)" 에 "code="
"Token Value Suffix(토큰 값 접미사)" 에 ".KS"
"Delimiter(구분자)" 에 " OR " 를 추가한다.
이 부분을 추가하면 "preview(미리보기)" 에 변수가 어떻게 만들어지는 확인할 수 있다.
지금은 선택된 값에 대해 "code=$code1$.KS OR code=$code2$.KS ..." 형식으로 만들어 주고자 한다.
자 이렇게 해서 우선 상단 사용자 입력 만드는 부분은 완성했다.
이제 몬테카를로스 포트폴리오 차트를 만들어보자.
이번에 작업할 앱은 stock이 아닌 "Splunk_ML_Toolkit"이다.
($SPLUNK_HOME/etc/apps/Splunk_ML_Toolkit)
작업할 위치는 다음과 같다.
- ${ML_Toolkit}/local/algos.conf
- ${ML_Toolkit}/bin/algos/MoteCarloSim.py
1. conf 파일을 추가한다.
- 사용할 알고리즘 이름만 추가해 주면 된다.
$ vi ${ML_Toolkit}/local/algos.conf
[MonteCarloSim]세부 과정

- 당황스럽게, local 디렉토리가 없다.
- 별거 아니니까, 그냥 만들어주고 .conf 파일도 쿨하게 만들어주자.

- 바보 같이 Splunk_ML_Toolkit에 만들어줬지만 디렉토리야 옮기면 되니까 어쨌든
- 오늘도 우당탕탕 해결!
2. python 파일을 추가한다.
- 전체 소스는 다음과 같다.
$ vi ${ML_Toolkit}/bin/algos/MonteCarloSim.py#!/usr/bin/env python
import pandas as pd
import numpy as np
from base import BaseAlgo, TransformerMixin
from codec import codecs_manager
from util.param_util import convert_params
class MonteCarloSim(BaseAlgo):
def __init__(self, options):
feature_variables = options.get('feature_variables', {})
target_variable = options.get('target_variable', {})
if len(feature_variables) == 0:
raise RuntimeError('You must spply one or more fields')
if len(target_variable) > 0:
raise RuntimeError('MonteCarloSim does not support the from clause')
# Check to see if parameters exist
params = options.get('params', {})
# Check if method is in parameters in search
if 'counter' in params:
self.counter = int(params['counter'])
else:
self.counter = 5000
# Check for bad parameters
if len(params) > 1:
raise RuntimeError('The only valid parameter is counter.')
def fit(self, df, options):
""" Compute the Monte Carlo Simulator """
# df contains all the search results, including hidden fields
# but the requested are saved as self.feature_variables
input_df = df[self.feature_variables]
input_df.sort_values(by=['date'])
input_df.set_index('date', inplace=True)
codes = input_df.columns
days = input_df.shape[0]/len(codes)
daily_ret = input_df.pct_change()
annual_ret = daily_ret.mean() * days
daily_cov = daily_ret.cov()
annual_cov = daily_cov * days
port_ret = []
port_risk = []
port_weights = []
for _ in range(self.counter):
weights = np.random.random(len(codes))
weights /= np.sum(weights)
returns = np.dot(weights, annual_ret)
risk = np.sqrt(np.dot(weights.T, np.dot(annual_cov, weights)))
port_ret.append(returns)
port_risk.append(risk)
port_weights.append(weights)
portfolio = { 'Returns' : port_ret, 'Risk': port_risk }
for i, s in enumerate(codes):
portfolio[s] = [weight[i] for weight in port_weights]
output_df = pd.DataFrame(portfolio)
output_df = output_df[['Returns', 'Risk'] + [s for s in codes]]
return output_df알고리즘 자체는 위의 책의 내용을 가져온 것이기 때문에 따로 설정하지 않고,
새로운 알고리즘을 추가하는 부분만 설명한다.
알고리즘을 새로 생성하기 위해서는 MLTK의 BaseAlgo를 상속받아서 필요한 함수들을 구현해 주어야 한다.
class MonteCarloSim(BaseAlgo):
상속 받아서 구현행야하는 함수들은 다음과 같다.
|
Method
|
Required
|
Arguements
|
|
__init__
|
YES
|
self, options
|
|
fit
|
YES
|
self, df, options
|
|
apply
|
Only for saved models
|
self, df, options
|
|
register_codes
|
Only for saved models
|
(none)
|
|
partial_fit
|
No
|
self, df, options
|
|
summary
|
No
|
self, options
|
여기에서는 실제 모델을 생성하는 알고리즘이 아니기 때문에 __init__와 fit 함수만 필요하다.
학습 모델을 만들기 위해서는 스플렁크의 다음 메뉴얼을 참고하자.
https://docs.splunk.com/Documentation/MLApp/latest/API/SupportVectorRegressor
Support Vector Regressor example - Splunk Documentation
Support Vector Regressor example This example adds scikit-learn's Support Vector Regressor algorithm to the Splunk Machine Learning Toolkit. This Support Vector Regressor example covers the following tasks: Using the BaseAlgo and a mixin Converting paramet
docs.splunk.com
2-1. __init__ 함수 만들기
- __init__함수란?
- SPL에서 오는 옵션들을 파싱해서 유효성을 검사하고 변수로 가지고 있는 부분을 처리한다.
def __init__(self, options):
feature_variables = options.get('feature_variables', {}) # 알고리즘에 사용할 컬럼들
target_variable = options.get('target_variable', {}) # 알고리즘의 from절에 사용하는 필드로 여기에서는 사용하지 않음
if len(feature_variables) == 0: # 컬럼이 정의되지 않으면 에러 발생
raise RuntimeError('You must spply one or more fields')
if len(target_variable) > 0: # 타겟 필드가 있으면 에러 발생
raise RuntimeError('MonteCarloSim does not support the from clause')
# 알고리즘에 있는 옵션들
params = options.get('params', {})
# 시뮬레이션을 할 개수를 설정하고 설정되어 있지 않으면 5,000번을 수행한다.
if 'counter' in params:
self.counter = int(params['counter'])
else:
self.counter = 5000
# 1개 이상의 파라미터가 존재하면 에러 발생
if len(params) > 1:
raise RuntimeError('The only valid parameter is counter.')2-1. fit 함수 만들기
- fit 함수란?
- 알고리즘을 수행하는 부분이다.
def fit(self, df, options):
""" Compute the Monte Carlo Simulator """
# df는 숨겨진 필드들을 포함해서 전달이 되는데,
# 알고리즘에서 필요한 필드들은 self.feature_variables 에 포함되어 있기 때문에
# 필요한 필드들만 선택한다.
input_df = df[self.feature_variables]
##### 이후에는 필요한 알고리즘을 DataFrame을 이용해 필요한 알고리즘을 수행하는 부분이다.
...
# 수행한 만들어진 DataFrame 을 리턴하면 splunk 에 다시 전달된다.
return output_df알고리즘을 만들어서 포함시키기 위해서는 충분히 python 의 다른 툴(jupyter)에서 테스트를 완료한 후 추가하도록 하자.
3. MLTK 에서 설정에서 MonteCarloSim 으로 검색해서 확인하고 차트만들기

이제 검색 창으로 가서 아래 코드로 검색하자
index="kospi" code=001040.KS OR code=034220.KS OR code=005930.KS OR code=017670.KS earliest=-365d
| rex field=code "^(?<code>\d+).KS"
| lookup kospi_200 code OUTPUT name
| rename Date as date
| rename name as code
| chart latest(Close) as value by date, code
| rename * as S_*
| rename S_date as date
| fit MonteCarloSim counter=10000 date, S_*
| table Risk, Returns, S_*
| table Risk, Returns
우당탕탕 여러가지 시도의 흔적

- 룩업이 없다는 뚱딴지 같은 소리를 한다.
- 권한이 없을 가능성이 농후함.

- 이런거 스스로 맞출때마다 약간 짜릿해.
- 좀 성장한 것 같은 느낌적인 느낌
- 권한 클릭

- object 표시 위치를 "이 앱만(stock)"에서 "모든 앱(시스템)"으로 변경
근데 아직도 실패
- 자세히 보니 lookup 이름이 kospi_200.csv다.
- 명령어를 아래와 같이 수정한다.
| lookup kospi_200 code OUTPUT name
위를 아래로 변경한다.
| lookup kospi_200.csv code OUTPUT name
오늘도 우당탕탕 성공
위의 명령을 수행해서 데이터를 제대로 가져왔으면 데이터를 "Scatter Chart"로 만들어서 새로운 대시보드에 저장한다.
대시보드 이름은 "포트폴리오 분석"
패널 이름은 "몬테카를로 포트폴리오"
험난한 과정 기록

- "나의 자산"이 보이지 않는다.
- 보나나마 권한 문제다.
- stock의 대시보드로 들어가자

- "나의 자산"의 공유 상태가 "비공개" 상태이다.
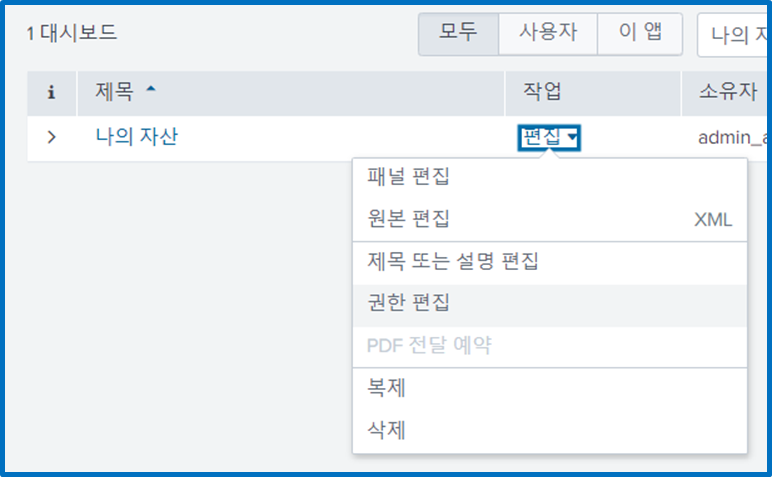
- 이걸 수정하기 위해서 "작업" 컬럼의 "편집"의 "권한 편집"을 클릭한다.

- 모든 앱을 클릭하고 admin 사용자의 읽기와 쓰기를 모두 허용한다고 표시한 후 저장
이제 다시 Splunk Machine Learning Toolkit 으로 돌아가서
다른 이름으로 저장 > 기존 대시보드 를 차례로 클릭해보면

나의 자산이 짜짠하고 나온다.
근데 이게 필요없고
그냥 머신러닝 툴킷에서 만드는 거임... 멍청이...
아래에 있는 쿼리는 는 간단하게 샤프 비율을 계산하고 테이블로 만들어서 추가한다.
index="kospi" code=001040.KS OR code=034220.KS OR code=005930.KS OR code=017670.KS earliest=-365d
| rex field=code "^(?<code>\d+).KS"
| lookup kospi_200.csv code OUTPUT name
| rename Date as date
| rename name as code
| chart latest(Close) as value by date, code
| rename * as S_*
| rename S_date as date
| fit MonteCarloSim counter=5000 date, S_*
| table Risk, Returns, S_* | table Risk, Returns, S_*
| eval Sharpe_ratio = Returns / Risk
| table Sharpe_ratio, Risk, Returns, S_*
표에 색상 넣는 법

- 테이블 헤더의 붓 모양을 클릭해서 변경해주면 된다.

차트와 테이블에 있는 값들 역시 같은 데이터를 쓰기 때문에
"base" 쿼리로 묶어서 한 번만 호출하도록 만든다.
그리고 종목 부분은 $codes$로 변수를 받을 예정임
<form>
<label>포트폴리오 분석</label>
<search id="monte">
<query>
index="kospi" $codes$ earliest=-365d
| rex field=code "^(?<code>\d+).KS"
| lookup kospi_200.csv code OUTPUT name
| rename Date as date
| rename name as code
| chart latest(Close) as value by date, code
| rename * as S_*
| rename S_date as date
| fit MonteCarloSim counter=10000 date, S_*
| table Risk, Returns, S_*
</query>
<earliest>0</earliest>
<latest></latest>
<sampleRatio>1</sampleRatio>
</search>
<fieldset submitButton="true">
<input type="multiselect" token="codes">
...
<row>
<panel>
<title>몬테카롤로스 포트폴리오</title>
<chart>
<search base="monte">
<query> table Risk, Returns</query>
</search>
...
<row>
<panel>
<title>포트폴리오 비율</title>
<table>
<search base="monte">
<query>table Risk, Returns, S_*
| eval Sharpe_ratio = Returns / Risk
| table Sharpe_ratio, Risk, Returns, S_*</query>
</search>
<option name="count">20</option>
...
완성!!!!
'Splunk > Splunk Project' 카테고리의 다른 글
| [ Splunk Project ] Splunk로 주식 분석 | Phase 8. 카카오톡에 알림 메시지 보내기 (0) | 2023.06.26 |
|---|---|
| [ Splunk Project ] Splunk로 주식 분석 | Phase 7. 주식 종목 추천 (0) | 2023.06.26 |
| [ Splunk Project ] Splunk로 주식 분석 | Phase 5. 주가 예측해 보기 (0) | 2023.06.22 |
| [ Splunk Project ] Splunk로 주식 분석 | Phase 4. 현재 나의 현황 대시보드 만들기 2 (0) | 2023.06.21 |
| [ Splunk Project ] Splunk로 주식 분석 | Phase 3. 현재 나의 현황 대시보드 만들기 (2) | 2023.06.21 |



