https://m.cafe.naver.com/ca-fe/web/cafes/26625693/articles/438?menuId=61
[스플렁크로 주식 데이터 분석 시스템을...] 1. 주식 데이터 수집하기
Cool 하게 시작해 보자... 이 과정을 모두 따라하기 위해서는 다양한 기술들이 필요하다. * 스플렁크와 SPL 에 대한 일반적인 지식 * Python + numpy ...
cafe.naver.com
요걸 참조로 많은 걸 시도했다..
다른 것들은 스무스하게 잘 할 수 있지만 오래된 게시글이라서 그런지 지금 돌리니 오류가 있는 부분이 있어서 포스팅한다.
크게 두 가지 부분에서 문제가 발생하는데
첫번째는 stock_json이라는 sourcetype을 지정하는 것에서 문제가 발생하고
두번째는 이 코드 자체에 문제가 있다.
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Fri Jul 19 12:00:44 2019
@author: cchoi
"""
from pandas_datareader import data
import pandas as pd
import argparse
from datetime import datetime, timedelta
import json
import os
import sys
CONF_PATH=os.path.dirname(os.path.abspath(__file__))
# 수집한 데이터를 실행한 디렉토리 및 /stock 에 텍스트 파일로 모을 것이다.
LOG_PATH=CONF_PATH + '/stock'
def write_log(f, df):
"""
수집한 데이터를 파일에 쓴다.
"""
json_string = df.to_json(orient='records') # Pandas에 있는 데이터 프레임을 json 형태로 변환한다.
json_obj = json.loads(json_string)
# Json array를 개별 이벤트로 만들기 위해 줄바꿈해서 입력한다.
# 스플렁크에서 JSON 타입은 작은 따옴표(') 가 아닌 큰 따옴표(") 로 되어 있어야 한다.
# 파이썬은 기본적으로 작은 따옴표로 만들어지기 때문에 replace 구문을 작성한다.
[f.write(str(val).replace("'", '"') + "\n") for val in json_obj]
def getStockHistory(companyCode, fromDate, toDate):
"""
Yahoo Financial 에서 주식데이터를 불러온다.
compandCode: 종목 코드 (kospi_200.csv 참조)
fromDate: 수집할 시작 날짜 (%Y-%m-%d 형태)
toDate: 수집할 마지막 날짜 (%Y-%m-%d 형태)
"""
dataSource = 'yahoo'
ticker = companyCode
print('===========>Call ' + ticker)
try:
start = pd.to_datetime(fromDate).date()
end = pd.to_datetime(toDate).date()
panel_data = data.DataReader(ticker, dataSource, start, end) # 이 한줄이면 해당 날짜에 대한 주식 데이터를 가져올 수 있다.
# 가져온 데이터를 우리의 입맛에 맞게 조금 고쳐준다.
df_reset =panel_data.reset_index()
df_reset['code'] = companyCode # 수집 된 데이터에는 종목 코드가 없기 때문에 새로 추가
df_reset['Date'] = df_reset['Date'].dt.strftime('%Y-%m-%d') # 날짜 형태 고정
return df_reset
except:
print(sys.exc_info()[0])
return None
def getCodeList():
"""
종목 코드 파일을 읽어서 가져온다.
"""
df = pd.read_csv(CONF_PATH + "/kospi_200.csv", dtype=str) # 파일을 읽는 것도 pandas를 이용하면 한줄로 가능하다.
return df.code.values
if __name__ == "__main__":
"""
메인 함수
--start_date : (Option)검색 시작 날짜로 %Y-%m-%d 형식을 취한다. (생략 시 어제 날짜)
--end_date : (Option)검색 종료 날짜로 %Y-%m-%d 형식을 취한다. (생략 시 어제 날짜)
--code : (Option) 검색할 종목 코드 (생략 시 kospi_200.csv 에 있는 전 종목)
"""
parser = argparse.ArgumentParser()
parser.add_argument('--start_date', help='start_date help')
parser.add_argument('--end_date', help='end_date help')
parser.add_argument('--code', help='code help')
args = parser.parse_args()
if args.start_date:
start_time = args.start_date
else:
start_time = (datetime.now() - timedelta(days=1)).strftime('%Y-%m-%d')
if args.end_date:
end_time = args.end_date
else:
end_time = (datetime.now() - timedelta(days=1)).strftime('%Y-%m-%d')
codes = []
if args.code:
codes.append(args.code)
else:
codes = getCodeList()
print("%s-%s",(start_time, end_time))
# 주식 종목을 조회하고 파일에 해당 내용을 쓴다.
with open(LOG_PATH + '/stocks_' + end_time.replace("-", "") + ".log" , "a") as f:
for code in codes:
result = getStockHistory(code + ".KS" , start_time, end_time)
if result is not None:
write_log(f, result)
f.close()$ python3 stock_monitor.py --start_date 2020-12-01 --end_date 2020-12-31
일단 첫번째 이야기부터 해보자.
sourcetype을 _json으로 지정을 하면 이 코드에서 수집한 날짜와 엔터프라이즈에서 수집할 때 기록한 _time 인덱스가 서로 다르다. 그래서 _time 인덱스를 수집한 시간과 날짜에서 이 주식 가격의 원래 시점으로 설정하기 위해서 시간을 잡을 수 있는 sourcetype을 새로 만드는 데 그 sourcetype이 stock_json이다.
그런데, 위 게시물 방식으로 sourcetype을 바꾸고 검색을 하여도 그 sourcetype은 여전히 _json임을 볼 수 있는데
그 이유는 splunk가 인덱싱을 수집 시에 진행하고 이미 수집된 데이터는 수정이 불가능하기 때문에 그렇다.
즉, 변경 이후로 전과 같은 디렉토리에 쌓이는 데이터는 sourcetype이 stock_json이지만
이미 수집된 데이터의 sourcetype은 _json이다.
이미 sourcetype이 _json으로 수집된 상황에서 수집된 데이터의 sourcetype을 stock_json으로 바꾸는 방법은
데이터를 지우고 다시 데이터를 입력하는 수 밖에 없다.
데이터는 indexer에 저장이 되기 때문에 Index를 지우면 올린 데이터가 모두 삭제되는 것을 확인할 수 있다.
또한 이 다음에 검색창에 sourcetype = stock_json이라고 검색을 하면 검색이 안 잡힌다.
이 문제를 해결하기 위해서는 권한 설정을 변경해줘하야하는데
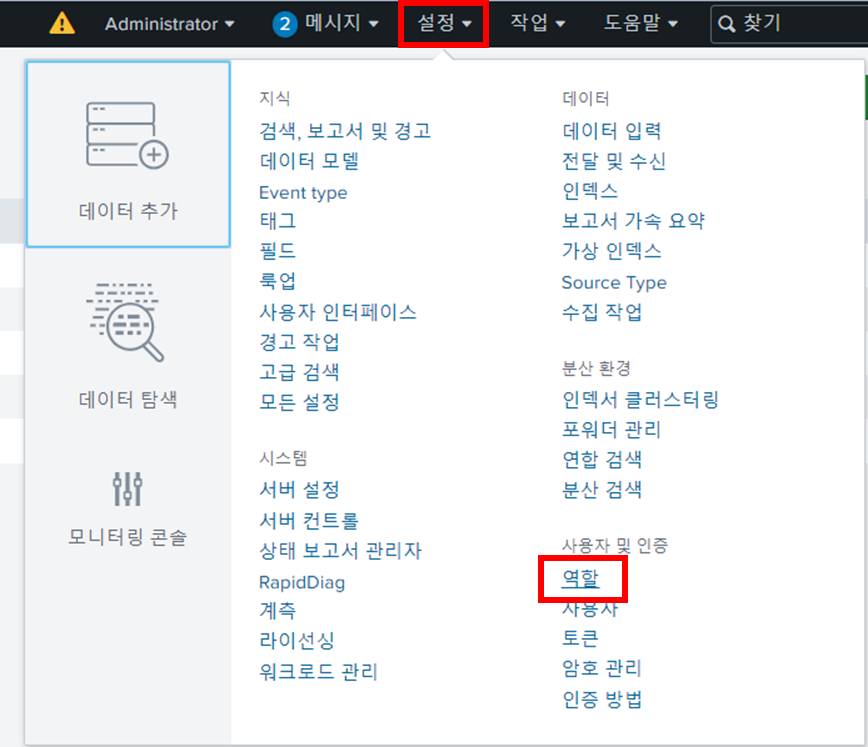
이 과정은 설정의 역할에 들어가서 진행된다.

원하는 사용자의 작업의 편집을 눌러서 설정한다.
나는 admin 계정을 사용하니 admin 계정의 작업을 수정했다.

요런 화면에서 기능을 눌러서

요 두 개의 항목의 체크박스에 체크를 눌러주면 권한이 생긴다.

이제 두 번째 yahoo finance의 API 형식이 변했다.
그래서 나는 이 문제를 해결하기 위해
import 하는 라이브러리를 변경하거나 주식을 받아오는 사이트를 바꿨다.
처음에는 야후한테 질려서 네이버로 주식을 받아오는 방법을 택했는데
뭔가 진 느낌이라서 다시 야후로도 성공해냈다.
naver는 pycham으로 진행했고, yahoo는 jupyter로 진행했다.
1. naver로 진행! (feat. pycharm)
일단 네이버로 진행하기 위해서 pandas_datareader를 설치하지 않고 pandas_datareader.naver로 변경해서 설치했다.
# from pandas_datareader import data
# 위의 라이브러리를 아래로 변경
import pandas_datareader.naver as web또한 위의 코드는 리눅스 운영체제를 기반으로 작성되어 있는 코드이기 때문에 디렉토리가 슬래시(/)로 작성되어 있음
나는 윈도우 운영체제를 기반으로 파이썬을 돌렸기 때문에 모두 역슬래시(\)로 변경해줬다.
import를 다른 모듈로 해주었기 때문에 명령어의 인수 구조가 조금 바뀐 관계로
pandel_data의 명령어를 조금 수정해줘야한다.
panel_data = data.DataReader(ticker, dataSource, start, end)
# 이 부분을 아래와 같이 수정해줘야한다.
panel_data = web.NaverDailyReader(ticker, start, end).read()
또한 start_time과 end_time에도 약간의 오류가 있는데
사실 지정한 기간의 주식 데이터를 받고 싶다면 큰 문제가 없지만
내가 오늘 날짜를 기준으로 가장 최근 데이터를 받고 싶다면 문제가 생긴다.
왜냐하면
start_time = (datetime.now() - timedelta(days=1)).strftime('%Y-%m-%d')
end_time = (datetime.now() - timedelta(days=1)).strftime('%Y-%m-%d')이 코드로 설정된 start-time과 end-time은
오늘이 만약에 2023년 06월 03일이라면
start_time도 end_time도 아래 코드의 설정 때문에 형식이 string으로 변해버렸기 때문에
start_time과 end-time 모두 2023년 06월 02일로 들어가게 되고
그게 위의 NaverDailyReader 함수에서는
두 *_time 모두 2023년 06월 02일 00시 00분 00초로 입력이 되어
그 사이 시간에 데이터가 없을 수 밖에 없는 상황이 발생한다.
그래서 그대들이 원하는 만큼의 간격을 주는 걸로 바꾸면 된다.
나는 아래와 같이 변경해줬다.
start_time = (datetime.now() - timedelta(days=7)).strftime('%Y-%m-%d')
end_time = (datetime.now() - timedelta(days=1)).strftime('%Y-%m-%d')
2. yahoo finance로 진행! (feat. jupyter notebook)
모듈 import는 다음과 같이 진행했다.
import pandas_datareader.data as web
import pandas as pd
import argparse
import yfinance as yf
yf.pdr_override()
from datetime import datetime, timedelta
import json
import os
import sys절대 경로를 얻는 __file__ 이라는 함수는
jupyter notebook으로 코드를 실행할 때는 통하지 않는다.
그래서 CONF_PATH = os.getcwd()라는 함수로 교체해 줘야함.
CONF_PATH=os.path.dirname(os.path.abspath(__file__))
# 위의 코드는 아래의 코드로 변경해줘야한다.
CONF_PATH=os.getcwd()마찬가지로 리눅스 기반의 슬래시(/)를
주피터 노트북이 윈도우 운영체제를 기반으로 돌아가기 때문에 모두 역슬래시(\)로 변경해줬다.
특별하게 argparse가 주피터에서는 잘 돌아가지 않는다.
그래서
args = parser.parse_args() 를
args = parser.parse_args('') 로 바꿔주었다.이후에 아까와 마찬가지로 날짜 설정을 다시 해주면 다시 성공!!
'Splunk > Splunk Project' 카테고리의 다른 글
| [ Splunk Project ] Splunk로 주식 분석 | Phase 3. 현재 나의 현황 대시보드 만들기 (1) | 2023.06.21 |
|---|---|
| [ Splunk Project ] Splunk로 주식 분석 | Phase 2. 실시간 주식 가격 조회 (0) | 2023.06.20 |
| [ Splunk 서버구축 ] splunk enterprise version up 하기, 업데이트 하기 (0) | 2023.06.15 |
| [ Splunk Project ] Splunk App 삭제하기 (0) | 2023.06.13 |
| [ Splunk Project : 서버 구축 ] Universal Forwarder 설치 디렉토리 변경하기 (0) | 2023.06.08 |



